学习《深度学习之TensorFlow》时的一些实践。
TF的基本使用
对于分类问题的特征X和标签Y,分别定义tf.placeholder,这是计算图输入数据的入口。
对于模型中的参数(注意不是超参数),如往往是权向量w和偏置b,定义tf.Variable,并传入初始的值,模型训练就是在改变这些参数的值。
定义前向结构,即计算图中,特征X以及前面的参数经过怎样的运算结合得到标签Y的预测值Z。
定义损失函数,它是基于Y和Z的一个具体的计算过程。
定义优化器,这是一个反向过程。因为是针对损失来做优化的,所以上一步定义的损失要传入这个优化器里。
定义tf.Variable的初始化过程,并定义好超参数,准备训练。
启动Session。
-
通过Session的
run()方法启动初始化过程。 -
对于每个epoch,通过Session的
run()方法启动优化器来训练模型参数。 -
上一步循环结束后,训练过程也就结束了,可以通过Session的
run()方法来查看损失、预测值Z等。
关闭Session。
要注意,除了启动初始化过程,其余的
run过程都需要通过参数feed_dict将具体的X传入,对于训练过程和计算损失的过程,还需要将Y传入。
在训练完成后,
tf.Variable如w和b是可以直接访问的,因为这决定了训练好的模型,而损失loss、预测值Z等都是依赖于输入的X和Y的,需要feed_dict将其传入。
一些小测试
定义常量
import tensorflow as tf
a = tf.constant(3)
b = tf.constant(4)
with tf.Session() as sess:
print("相加: %i" % sess.run(a + b))
print("相乘: %i" % sess.run(a * b))
相加: 7
相乘: 12
计算图中的运算结点
import tensorflow as tf
a = tf.placeholder(tf.int16)
b = tf.placeholder(tf.int16)
add = tf.add(a, b)
mul = tf.multiply(a, b)
with tf.Session() as sess:
print("相加: %i" % sess.run(add, feed_dict={a: 3, b: 4}))
print("相乘: %i" % sess.run(mul, feed_dict={a: 3, b: 4}))
print("一起取出多个结点:", sess.run([add, mul], feed_dict={a: 4, b: 5}))
取出检查点文件中的模型参数
这个是在下面的例子生成的检查点文件的基础上的。
from tensorflow.python.tools.inspect_checkpoint import print_tensors_in_checkpoint_file
savedir = "../z3/"
# 默认情况下,Saver使用tf.Variable.name属性来保存变量
# 这里用print_tensors_in_checkpoint_file()输出其中所有变量和它的值
print_tensors_in_checkpoint_file(savedir + "linermodel.ckpt-18", tensor_name=None, all_tensors=True)
tensor_name: bias
[-0.05547838]
tensor_name: weight
[2.0291195]
拟合线性回归模型并使用检查点
除了上面的流程外,这里选择了在epoch为偶数时将模型保存在检查点文件中。之所以这样做(而不是在训练完成再保存),是因为训练模型时可能因为各种原因中断训练,用这种方式至少可以确保记录了中间的结果,即使训练中途崩了,下次也不必重新训练,只要拿出模型继续训练就好了。
注意38行的saver = tf.train.Saver(max_to_keep=1),这可以保证只保存一个检查点文件,这样每次就会覆盖掉之前保存的,而只保留最新的。
在程序的最后从检查点中读取了模型,并做了预测。这里发现和模型训练完后的预测值不一样,因为这个程序里最后一次保存检查点并不是模型训练完的那一次(少了一次,epoch实际是0~19而在18时做了最后一次保存)。
import tensorflow as tf
import numpy as np
from matplotlib import pyplot as plt
import math
# 生成样本,y=2x噪声上下0.1
X_train = np.linspace(-1, 1, 100)
Y_train = 2 * X_train + np.random.randn(*X_train.shape) * 0.2 - 0.1
# plt.plot(X_train, y_train, 'ro', label="原始数据")
# plt.legend()
# plt.show()
"""建立模型"""
# 占位符
X = tf.placeholder("float")
Y = tf.placeholder("float")
# 模型参数
W = tf.Variable(tf.random_normal([1]), name="weight") # 一维的权重w_1,初始化为-1到1的随机数
b = tf.Variable(tf.zeros([1]), name="bias") # 一维的偏置b,初始化为0
# (1)前向结构:通过正向生成一个结果
Z = tf.multiply(X, W) + b
# (2)定义损失的计算:这里就是所有的y和z的差的平方的平均值
# reduce_mean用于计算指定axis的平均值,未指定时则对tensor中每个数加起来求平均
cost = tf.reduce_mean(tf.square(Y - Z)) # <class 'tensorflow.python.framework.ops.Tensor'>
# (3)反向优化:通过反向过程调整模型参数.这里使用学习率为0.01的梯度下降最小化损失cost
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)
"""迭代训练模型"""
# 初始化过程:初始化所有的变量
init = tf.global_variables_initializer()
# 模型的超参数,这里epoch是模型会完整学习多少次样本
train_epochs = 20
# 这个仅仅是控制每多少个epoch显示下模型的详细信息
display_step = 2
# tf.train.Saver用于保存模型到文件/从文件中取用模型
# 使用了检查点,这里指定max_to_keep=1即在迭代过程中只保存一个文件
# 那么在循环训练中,新生成的模型会覆盖之前的模型
saver = tf.train.Saver(max_to_keep=1)
# 启动Session,这种方式不用手动关闭Session
with tf.Session() as sess:
# 运行初始化过程
sess.run(init)
# 用于记录批次和损失
plotdata = {"ephch": [], "loss": []}
# 向模型输入数据,对于每个epoch
for epoch in range(train_epochs):
# 都要遍历模型中所有的样本(x,y)
for (x, y) in zip(X_train, Y_train):
# 运行优化器,填充模型中X,Y占位符的内容为这个具体的样本(x,y)
sess.run(optimizer, feed_dict={X: x, Y: y})
# 每display_step个epoch显示一下训练中的详细信息
if epoch % display_step == 0:
# 计算下损失.每次要计算中间变量的当前值时候都要sess.run得到
loss = sess.run(cost, feed_dict={X: X_train, Y: Y_train})
print("Epoch:", epoch, "cost=", loss, "W=", sess.run(W), "b=", sess.run(b))
# 如果损失存在,将该批次和对应损失记录下来
if loss != "NA":
plotdata["ephch"].append(epoch)
plotdata["loss"].append(loss)
"""保存检查点"""
# 这里选择在每次输出信息后保存一下检查点,同时使用global_step记录epoch次数
saver.save(sess, "./linermodel.ckpt", global_step=epoch)
print("完成,cost=", sess.run(cost, feed_dict={X: X_train, Y: Y_train}), "W=", sess.run(W), "b=", sess.run(b))
# 提前计算出结果以在Session外也能使用,下面这种方式都可以
result = sess.run(W) * X_train + sess.run(b)
result2 = sess.run(Z, feed_dict={X: X_train})
# 这里验证一下它们中对应项的值是相等的
for k1, k2 in zip(result, result2):
assert math.isclose(k1, k2, rel_tol=1e-5)
"""使用模型"""
# 如果要使用模型,直接将样本的值传入并计算输出Z即可
print("对x=5的预测值:", sess.run(Z, feed_dict={X: 5}))
"""保存模型到文件"""
# saver.save(sess, "./linermodel.ckpt")
"""训练模型可视化"""
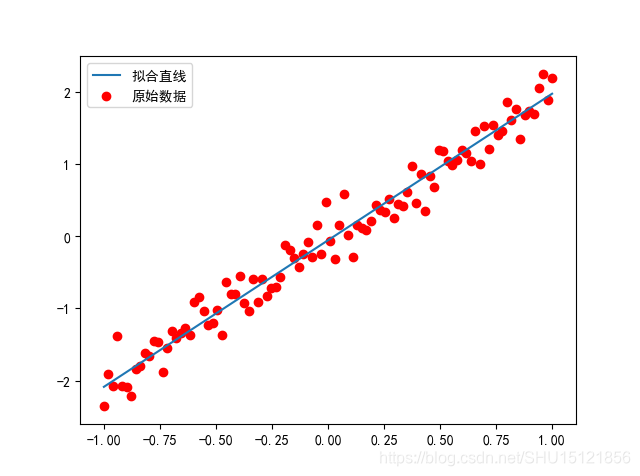
plt.scatter(X_train, Y_train, c='r', marker='o', label="原始数据")
plt.plot(X_train, result, label="拟合直线")
plt.legend()
plt.show()
def moving_average(a, w=10):
"""
对损失序列a,生成w-平均损失序列
即每个位置的损失由其和其前的共w个损失的平均来代替
"""
if len(a) < w: # 当w太小不足以计算任何元素的平均时
return a[:] # 直接返回a的复制
return [val if idx < w else sum(a[idx - w:idx]) / w for idx, val in enumerate(a)]
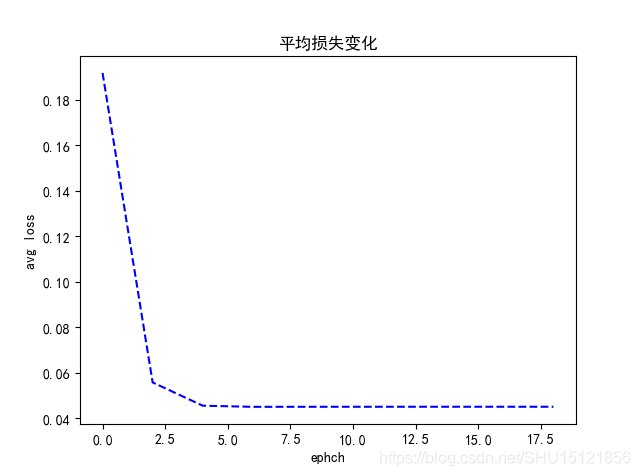
"""绘制平均loss变化曲线"""
plotdata["avgloss"] = moving_average(plotdata["loss"])
plt.plot(plotdata["ephch"], plotdata["avgloss"], 'b--')
plt.xlabel("ephch")
plt.ylabel("avg loss")
plt.title("平均损失变化")
plt.show()
"""从文件载入模型"""
with tf.Session() as sess2:
sess2.run(init) # 还是需要运行一下初始化过程
# saver.restore(sess2, "./linermodel.ckpt")
# 在当前目录下寻找最近的检查点并载入
ckpt = tf.train.latest_checkpoint("./")
if ckpt is not None:
saver.restore(sess2, ckpt)
print("对x=5的预测值:", sess2.run(Z, feed_dict={X: 5}))
Epoch: 0 cost= 0.1917328 W= [1.4377091] b= [0.12655073]
Epoch: 2 cost= 0.055657808 W= [1.871314] b= [0.00432279]
Epoch: 4 cost= 0.04542881 W= [1.9882357] b= [-0.03980212]
Epoch: 6 cost= 0.044927694 W= [2.0185487] b= [-0.05142205]
Epoch: 8 cost= 0.044943742 W= [2.0263882] b= [-0.05443016]
Epoch: 10 cost= 0.044957623 W= [2.028414] b= [-0.05520765]
Epoch: 12 cost= 0.044961873 W= [2.0289385] b= [-0.05540875]
Epoch: 14 cost= 0.044963013 W= [2.029074] b= [-0.05546085]
Epoch: 16 cost= 0.044963315 W= [2.0291097] b= [-0.05547457]
Epoch: 18 cost= 0.044963405 W= [2.0291195] b= [-0.05547838]
完成,cost= 0.04496341 W= [2.0291212] b= [-0.05547896]
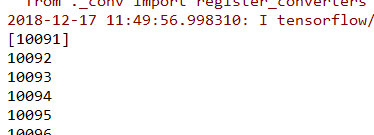
对x=5的预测值: [10.090127]
 对x=5的预测值: [10.090119]
对x=5的预测值: [10.090119]
按照时间自动管理检查点
书上用一个全局张量每次自增1为例。
import tensorflow as tf
'''
按照时间保存检查点
'''
# 清除默认图堆栈,重置全局的默认图
tf.reset_default_graph()
# 创建(如果需要的话)并返回global step tensor,默认参数graph=None即使用默认图
# 当用这种方法按照时间保存检查点时,必须要定义这个global step张量
global_step = tf.train.get_or_create_global_step()
# 这里是为global_step张量每次增加1
step = tf.assign_add(global_step, 1)
# 通过MonitoredTrainingSession实现按时间自动保存,设置检查点保存目录,设置保存间隔为2秒
with tf.train.MonitoredTrainingSession(checkpoint_dir='log/checkpoints', save_checkpoint_secs=2) as sess:
# 输出一下当前global_step这个张量的值
print(sess.run([global_step]))
# 这里是一个死循环,只要sess不结束就一直循环
while not sess.should_stop():
# 运行step,即为global_step这个张量增加1
i = sess.run(step)
# 每次运行都输出一下
print(i)
多次运行可以发现数字(global_step这个张量的值)并不会从头开始,而是因为每2秒保存一次,从上次保存的检查点开始。
如某次的运行结果如下: